🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
Pour démarrer
Bienvenue dans la programmation asynchrone avec Rust ! Si vous voulez commencer à écrire du code asynchrone avec Rust, vous êtes au bon endroit. Que vous soyez en train de construire un serveur web, une base de données, ou un système d'exploitation, ce livre va vous montrer comment utiliser les outils de programmation asynchrone de Rust pour exploiter au mieux votre matériel.
Ce que ce livre va traiter
Ce livre vise à être un guide étendu et à jour sur l'utilisation des bibliothèques et fonctionnalités asynchrones du langage Rust, aussi bien pour les débutants que pour les habitués.
-
Les chapitres du début initient à la programmation asynchrone en général, et comment Rust l'a interprété.
-
Les chapitres intermédiaires présentent les principaux utilitaires et outils de contrôle que vous pouvez utiliser lorsque vous écrivez du code asynchrone, et explique les bonnes pratiques pour structurer les bibliothèques et les applications afin d'optimiser les performances et la réutilisation.
-
La dernière section du livre aborde plus largement l'écosystème asynchrone, et propose un certain nombre d'exemples pour répondre à des besoins courants.
Maintenant que vous savez cela, commençons à explorer le monde excitant de la programmation asynchrone avec Rust !
Ce livre est la traduction française de la version Anglaise du livre Asynchronous Programming in Rust. Si vous souhaitez contribuer à cette traduction, vous trouverez le dépôt de son code sur GitHub.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
Pourquoi l'asynchrone ?
Nous apprécions tous la façon dont Rust nous permet d'écrire rapidement des programmes sûrs. Mais comment la programmation asynchrone s'inscrit-elle dans cette démarche ?
La programmation asynchrone, abrégé async, est un modèle de programmation
concurrent pris en charge par un nombre croissant de langages de
programmation. Il vous permet d'exécuter un grand nombre de tâches concurrentes
sur un petit nombre de processus du Système d'Exploitation, tout en conservant
l'apparence et la convivialité de la programmation synchrone habituelle, grâce
à la syntaxe async/await.
L'asynchrone et les autres modèles de concurrence
La programmation concurrente est moins mûre et moins "formalisée" que la programmation séquentielle classique. Par conséquent, nous formulons la concurrence différemment selon le modèle de programmation pris en charge par le langage. Un bref panorama des modèles de concurrence les plus populaires peut vous aider à comprendre où se situe la programmation asynchrone dans le domaine plus large de la programmation asynchrone :
- Les processus du système d'exploitation ne nécessitent aucun changement dans le modèle de programmation, ce qui facilite l'expression de la concurrence. Cependant, la synchronisation entre les processus peut être difficile, et la conséquence sur les performances est importante. Les groupes de processus peuvent réduire certains coûts, mais pas suffisamment pour faire face à la charge de travail d'une grosse masse d'entrées/sorties.
- La programmation orientée évènements, conjuguée avec les fonctions de rappel, peut s'avérer très performante, mais a tendance à produire un contrôle de flux "non-linéaire" et verbeux. Les flux de données et les propagations d'erreurs sont souvent difficiles à suivre.
- Les coroutines, comme les processus, ne nécessitent pas de changements sur le modèle de programmation, ce qui facilite leur utilisation. Comme l'asynchrone, elles peuvent supporter de nombreuses tâches. Cependant, elles font abstraction des détails de bas niveau, qui sont importants pour la programmation système et les implémentations personnalisées d'environnements d'exécution.
- Le modèle acteur divise tous les calculs concurrents en différentes parties que l'on appelle acteurs, qui communiquent par le biais de passage de messages faillibles, comme dans les systèmes distribués. Le modèle d'acteur peut être implémenté efficacement, mais il ne répondra pas à tous les problèmes, comme le contrôle de flux et la logique de relance.
En résumé, la programmation asynchrone permet des implémentations très performantes qui sont nécessaires pour des langages bas-niveau comme Rust, tout en offrant les avantages ergonomiques aux processus et aux coroutines.
L'asynchrone en Rust et dans les autres langages
Bien que la programmation asynchrone soit prise en charge dans de nombreux langages, certains détails changent selon les implémentations. L'implémentation en Rust de async se distingue des autres langages de plusieurs manières :
- Les futures sont inertes en Rust et progressent uniquement lorsqu'elles sont sollicitées. Libérer une future va arrêter sa progression.
- L'asynchrone n'a pas de coût en Rust, ce qui signifie que vous ne payez que ce que vous utilisez. Plus précisément, vous pouvez utiliser async sans allouer sur le tas et sans répartition dynamique, ce qui est très intéressant pour les performances ! Cela vous permet également d'utiliser async dans des environnements restreints, comme par exemple sur des systèmes embarqués.
- Il n'y a pas d'environnement d'exécution intégré par défaut dans Rust. Par contre, des environnements d'exécution sont disponibles dans des crates maintenues par la communauté.
- Des environnements d'exécution mono-processus et multi-processus existent en Rust, qui ont chacun leurs avantages et inconvénients.
L'asynchrone et les processus en Rust
La première alternative à l'asynchrone en Rust est d'utiliser les processus du
Système d'Exploitation, soit directement via
std::thread, soit indirectement via
un groupe de processus.
La migration des processus vers de l'asynchrone et vice-versa nécessite
généralement un gros chantier de remaniement, que ce soit pour leur implémentation
ou pour leurs interfaces publique (si vous écrivez une bibliothèque) . Par
conséquent, vous pouvez vous épargner beaucoup de temps de développement si
vous choisissez très tôt le modèle qui convient bien à vos besoins.
Les processus de Système d'Exploitation sont préférables pour un petit nombre de tâches, puisque les processus s'accompagnent d'une surcharge du processeur et de la mémoire. Créer et basculer entre les processus est assez gourmand, car même les processus inutilisés consomment des ressources système. Une bibliothèque implémentant des groupe de tâches peut aider à atténuer certains coûts, mais pas tous. Cependant, les processus vous permet de réutiliser du code synchrone existant sans avoir besoin de changement significatif du code — il n'y a pas besoin d'avoir de modèle de programmation en particulier. Avec certains systèmes d'exploitation, vous pouvez aussi changer la priorité d'un processus, ce qui peut être pratique pour les pilotes et les autres utilisations sensibles à la latence.
L'asynchrone permet de réduire significativement la surcharge du processeur et de la mémoire, en particulier pour les charges de travail avec un grand nombre de tâches liées à des entrées/sorties, comme les serveurs et les bases de données. Pour comparaison à la même échelle, vous pouvez avoir un nombre bien plus élevé de tâches qu'avec les processus du Système d'Exploitation, car comme un environnement d'exécution asynchrone utilise une petite partie des (coûteux) processus pour gérer une grande quantité de tâches (peu coûteuses). Cependant, le Rust asynchrone produit des binaires plus lourds à cause des machines à états générés à partir des fonctions asynchrones et que par conséquent chaque exécutable embarque un environnement d'exécution asynchrone.
Une dernière remarque, la programmation asynchrone n'est pas meilleure que les processus, c'est différent. Si vous n'avez pas besoin de l'asynchrone pour des raisons de performance, les processus sont souvent une alternative plus simple.
Exemple : un téléchargement concurrent
Dans cet exemple, notre objectif est de télécharger deux pages web en concurrence. Dans une application traditionnelle avec des processus nous avons besoin de créer des processus pour appliquer la concurrence :
fn recuperer_deux_sites() {
// Crée deux tâches pour faire le travail.
let premiere_tache = std::thread::spawn(|| telecharger("https://www.foo.com"));
let seconde_tache = std::thread::spawn(|| telecharger("https://www.bar.com"));
// Attente que les deux tâches se terminent.
premiere_tache.join().expect("la première tâche a paniqué");
seconde_tache.join().expect("la deuxième tâche a paniqué");
}
Cependant, le téléchargement d'une page web est une petite tâche, donc créer un processus pour une si petite quantité de travail est un peu du gaspillage. Pour une application plus importante, cela peut rapidement devenir un goulot d'étranglement. Grâce au Rust asynchrone, nous pouvons exécuter ces tâches en concurrence sans avoir besoin de processus supplémentaires :
async fn recuperer_deux_sites_asynchrone() {
// Crée deux différentes "futures" qui, lorsqu'elles sont menée à terme,
// va télécharger les pages web de manière asynchrone.
let premier_future = telecharger_asynchrone("https://www.foo.com");
let second_future = telecharger_asynchrone("https://www.bar.com");
// Exécute les deux futures en même temps jusqu'à leur fin.
futures::join!(premier_future, second_future);
}
Notez bien que ici, il n'y a pas de processus supplémentaires qui sont créés. De plus, tous les appels à des fonctions sont distribués statiquement, et il n'y a pas d'allocation sur le tas ! Cependant, nous avons d'abord besoin d'écrire le code pour être asynchrone, ce que ce livre va vous aider à accomplir.
Les modèles personnalisés de concurrence en Rust
Une dernière remarque, Rust ne vous forçait pas à choisir entre les processus et l'asynchrone. Vous pouvez utiliser ces deux modèles au sein d'une même application, ce qui peut être utile lorsque vous mélangez les dépendances de processus et d'asynchrone. En fait, vous pouvez même utiliser un modèle de concurrence complètement différent en même temps, du moment que vous trouvez une bibliothèque qui l'implémente.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
L'état de l'art de l'asynchrone en Rust
Certaines parties du Rust asynchrone sont pris en charge avec les mêmes garanties de stabilité que le Rust synchrone. Les autres parties sont en cours de perfectionnement et évolueront dans le temps. Voici ce que vous pouvez attendre du Rust asynchrone :
- D'excellentes performances à l'exécution des charges de travail en concurrence classiques.
- Une interaction plus régulière avec les fonctionnalités avancées du langage, comme les durées de vie et l'épinglage.
- Des contraintes de compatibilité, à la fois entre le code synchrone et asynchrone, et entre les différents environnements d'exécution.
- Une plus grande exigence de maintenance, à cause de l'évolution continue des environnements d'exécution asynchrones et du langage.
En résumé, le Rust asynchrone est plus difficile à utiliser et peut demander plus de maintenance que le Rust synchrone, mais il vous procure en retour les meilleures performances dans le domaine. Tous les éléments du Rust asynchrone dont en constante amélioration, donc les effets de ces contre-parties s'estomperont avec le temps.
La prise en charge des bibliothèques et du langage
Bien que la programmation asynchrone soit fournie par le coeur de Rust, la plupart des applications asynchrones dépendent des fonctionnalités offertes par les crates de la communauté. Par conséquent, vous devez avoir recours à un mélange de fonctionnalités offertes par le langage et les bibliothèques :
- Les traits, types et fonctions les plus fondamentaux, comme le trait
Future, sont fournis par la bibliothèque standard. - La syntaxe
async/awaitest prise en charge directement par le compilateur Rust. - De nombreux types, macros et fonctions utilitaires sont fournis par la crate
futures. Ils peuvent être utilisés dans de nombreuses applications asynchrones en Rust. - L'exécution du code asynchrone, les entrées/sorties, et la création de tâches sont prises en charge par les "environnements d'exécution asynchrone", comme Tokio et async-std. La plupart des applications asynchrones, et certaines crates asynchrones, dépendent d'un environnement d'exécution précis. Vous pouvez consulter la section "L'écosystème asynchrone" pour en savoir plus.
Certaines fonctionnalités du langage auquel vous êtes habitué en Rust synchrone peuvent ne pas encore être disponible en Rust asynchrone. Par exemple, Rust ne vous permet pas encore de déclarer des fonctions asynchrones dans des traits. Par conséquent, vous avez besoin de mettre en place des solutions de substitution pour arriver au même résultat, ce qui peut rendre les choses un peu plus verbeuses.
La compilation et le débogage
Dans la plupart des cas, les erreurs du compilateur et d'exécution du Rust asynchrone fonctionnent de la même manière qu'elles l'ont toujours fait en Rust. Voici quelques différences intéressantes :
Les erreurs de compilation
Les erreurs de compilateur en Rust asynchrone suivent les mêmes règles strictes que le Rust synchrone, mais comme le Rust asynchrone dépend souvent de fonctionnalités du langage plus élaborées, comme les durées de vie et l'épinglage, vous pourriez rencontrer plus régulièrement ces types d'erreurs.
Les erreurs à l'exécution
A chaque fois que le compilateur va rencontrer une fonction asynchrone, il va générer une machine à états en arrière-plan. Les traces de la pile en Rust asynchrone contiennent généralement des informations sur ces machines à états, ainsi que les appels de fonctions de l'environnement d'exécution. Par conséquent, l'interprétation des traces de la pile peut être un peu plus ardue qu'elle le serait en Rust synchrone.
Les nouveaux types d'erreurs
Quelques nouveaux types d'erreurs sont possibles avec Rust asynchrone, par
exemple si vous appelez une fonction bloquante à partir d'un contexte
asynchrone ou si vous n'implémentez pas correctement le trait Future. Ces
erreurs peuvent ne pas être signalées par le compilateur et parfois même ne
peuvent pas être couvertes par vos tests unitaires. Le but de ce livre est
de vous apprendre les principes fondamentaux pour vous aider à éviter ces
pièges.
Remarques à propos de la compatibilité
Le code asynchrone et synchrone ne peuvent pas toujours être combinés librement. Par exemple, vous ne pouvez pas appeler directement une fonction asynchrone à partir d'une fonction synchrone. Le code synchrone et asynchrone ont aussi tendance à favoriser des motifs de conception différents, ce qui peut rendre difficile de combiner du code destiné aux différents environnements.
Et même le code asynchrone ne peut pas être combiné librement. Certaines crates dépendent d'un environnement d'exécution asynchrone pour fonctionner. Si c'est le cas, c'est souvent précisé dans la liste des dépendances de la crate.
Ces problèmes de compatibilité peuvent réduire vos options, donc il vaut mieux faire assez tôt vos recherches sur les environnements d'exécution asynchrone et de leurs crates associées. Une fois que vous vous êtes installé dans un environnement d'exécution, vous n'aurez plus à vous soucier de la compatibilité.
Les performances
Les performances du Rust asynchrone dépend de l'implémentation de l'environnement d'exécution asynchrone que vous choisissez. Même si les environnements d'exécution qui propulsent les applications asynchrones en Rust sont relativement récents, ils sont remarquablement performants pour la plupart des charges de travail.
Ceci étant dit, la plupart des écosystèmes asynchrones prévoient un environnement d'exécution multi-processus. Cela rend plus difficile d'apprécier les bienfaits sur les performances théoriques des applications asynchrone sur un seul processus, appelée aussi synchronisation allégée. Un autre domaine d'application sous-côté est celui des tâches sensibles à la latence, qui sont importantes pour les pilotes, les applications avec interface graphique, parmi d'autres. Ces tâches dépendent de l'environnement d'exécution et/ou de la prise en charge du système d'exploitation pour être orchestrées correctement. Vous pouvez donc espérer une meilleure prise en charge à l'avenir des bibliothèques de ces cas d'usages.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
Introduction à async et await
Le async et await sont les outils intégrés dans Rust pour écrire des
fonctions asynchrones qui ressemblent à du code synchrone. async transforme
un bloc de code en une machine à états qui implémente le trait Future. Alors
que l'appel à une fonction bloquante dans une méthode synchrone va bloquer tout
le processus, les Futures bloquées céderont le contrôle du processus,
permettant aux autres Futures de s'exécuter.
Ajoutons quelques dépendances au fichier Cargo.toml :
[dependencies]
futures = "0.3"
Pour créer une fonction asynchrone, vous pouvez utiliser la syntaxe
async fn :
#![allow(unused)] fn main() { async fn faire_quelquechose() { /* ... */ } }
La valeur retournée par async fn est une Future. Pour que quelque chose se
produise, la Future a besoin d'être exécutée avec un exécuteur.
// `block_on` bloque le processus en cours jusqu'à ce que la future qu'on lui // donne ait terminé son exécution. Les autres exécuteurs ont un comportement // plus complexe, comme par exemple ordonnancer plusieurs futures sur le même // processus. use futures::executor::block_on; async fn salutations() { println!("salutations !"); } fn main() { let future = salutations(); // rien n'est pas affiché block_on(future); // `future` est exécuté et "salutations !" est affiché }
Dans une async fn, vous pouvez utiliser .await pour attendre la fin d'un
autre type qui implémente le trait Future, comme le résultat d'une autre
async fn. Contrairement à block_on, .await ne bloque pas le processus en
cours, mais attends plutôt de manière asynchrone que la future se termine, pour
permettre aux autres tâches de s'exécuter si cette future n'est pas en mesure de
progresser actuellement.
Par exemple, imaginons que nous ayons trois async fn : apprendre_chanson,
chanter_chanson, et danser :
async fn apprendre_chanson() -> Chanson { /* ... */ }
async fn chanter_chanson(chanson: Chanson) { /* ... */ }
async fn danser() { /* ... */ }
Une façon d'apprendre, chanter, et danser serait de bloquer sur chacun :
fn main() {
let chanson = block_on(apprendre_chanson());
block_on(chanter_chanson(chanson));
block_on(danser());
}
Cependant, nous ne profitons pas de performances optimales de cette manière —
nous ne faisons qu'une seule chose à fois ! Il faut que nous apprenions la
chanson avant de pouvoir la chanter, mais il reste possible de danser en même
temps qu'on apprends et qu'on chante la chanson. Pour pouvoir faire cela, nous
pouvons créer deux async fn qui peuvent être exécutés en concurrence :
async fn apprendre_et_chanter() {
// Attends (await) que la chanson soit apprise avant de la chanter.
// Nous utilisons ici `.await` plutôt que `block_on` pour éviter de bloquer
// le processus, ce qui rend possible de `danser` en même temps.
let chanson = apprendre_chanson().await;
chanter_chanson(chanson).await;
}
async fn async_main() {
let f1 = apprendre_et_chanter();
let f2 = danser();
// `join!` se comporte comme `.await`, mais permet d'attendre plusieurs
// futures en concurrence. Si nous avions bloqué temporairement dans la
// future `apprendre_et_chanter`, la future `danser` aurais pris le relais
// dans le processus d'exécution en cours. Si `danser` se bloque aussi,
// `apprendre_et_chanter` pourra continuer dans le processus en cours. Si
// les deux futures sont bloquées, et bien `async_main` est bloqué et va en
// informer son exécuteur.
futures::join!(f1, f2);
}
fn main() {
block_on(async_main());
}
Dans cet exemple, la chanson doit être apprise avant de chanter la chanson,
mais l'apprentissage et le chant peuvent se dérouler en même temps qu'on
danse. Si nous avions utilisé block_on(apprendre_chanson()) plutôt que
apprendre_chanson().await dans apprendre_et_chanter, le processus n'aurait
rien pu faire tant que apprendre_chanson s'exécutait. Cela aurait rendu
impossible de pouvoir danser en même temps. En attendant la future
apprendre_chanson, grâce à await, nous permettons aux autres tâches de
prendre le relais dans le processus en cours d'exécution lorsque
apprendre_chanson est bloqué. Cela permet d'exécuter plusieurs futures
jusqu'à leur fin de manière concurrente au sein du même processus.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
Sous le capot : exécuter les Futures et les tâches
Dans cette section, nous allons étudier la structure sous-jacente de
l'ordonnancement des Futures et des tâches asynchrones. Si vous vous intéressez
uniquement à l'apprentissage de l'écriture de code de haut niveau qui utilise
les types Future existants et que vous n'êtes pas intéressés par détails du
fonctionnement des types Future, vous pouvez passer au chapitre suivant.
Cependant, certains sujets abordés dans ce chapitre sont utiles pour comprendre
comment le code de async et await fonctionne, comprendre l'environnement
d'exécution et les caractéristiques de performance du code async et await,
ainsi que la création de nouvelles primitives asynchrones.
Si vous décidez de sauter cette section, vous devriez le marquer pour revenir le
consulter à nouveau.
Maintenance que vous savez cela, commençons par parler du trait Future.
The Future Trait
Cette page n'a pas encore été traduite.
Consulter cette page en Anglais
Task Wakeups with Waker
Cette page n'a pas encore été traduite.
Consulter cette page en Anglais
Applied: Build an Executor
Cette page n'a pas encore été traduite.
Consulter cette page en Anglais
Executors and System IO
Cette page n'a pas encore été traduite.
Consulter cette page en Anglais
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
async et await
Dans le premier chapitre, nous avons présenté async et
await. Ce nouveau chapitre va aborder plus en détails async et await, en
expliquant comment il fonctionne et comment le code async se distingue des
programmes Rust traditionnels.
async et await sont des mot-clés spécifiques de la syntaxe Rust qui permet
de transférer le contrôle du processus en cours plutôt que de le bloquer,
ce qui permet à un autre code de progresser pendant que nous attendons que
cette opération se termine.
Il y a deux principaux moyens d'utiliser async : async fn et les blocs
async. Chacun retourne une valeur qui implémente le trait Future :
// `alpha()` retourne un type qui implémente `Future<Output = u8>`.
// `alpha().await` va retourner une valeur de type `u8`.
async fn alpha() -> u8 { 5 }
fn beta() -> impl Future<Output = u8> {
// Ce bloc `async` va retourner un type qui implémente
// `Future<Output = u8>`.
async {
let x: u8 = alpha().await;
x + 5
}
}
Comme nous l'avons vu dans le premier chapitre, les corps des async et des
autres futures sont passifs : ils ne font rien jusqu'à ce qu'ils soient
exécutés. La façon la plus courante d'exécuter une Future est d'utiliser
await sur elle. Lorsque await est utilisé sur une Future, il va tenter de
l'exécuter jusqu'à sa fin. Si la Future est bloquée, il va transférer le
contrôle du processus en cours. Lorsqu'une progression pourra être effectuée à
nouveau, la Future va être récupérée par l'exécuteur et va continuer son
exécution, ce qui permettra à terme au await de se résoudre.
Les durées de vie async
Contrairement aux fonctions traditionnelles, les async fn qui utilisent des
références ou d'autres arguments non static vont retourner une Future qui
est contrainte par la durée de vie des arguments :
// Cette fonction :
async fn alpha(x: &u8) -> u8 { *x }
// ... est équivalente à cette fonction :
fn alpha_enrichi<'a>(x: &'a u8) -> impl Future<Output = u8> + 'a {
async move { *x }
}
Cela signifie que l'on doit utiliser await sur la future retournée d'une
async fn uniquement pendant que ses arguments non static sont toujours en
vigueur. Dans le cas courant où on utilise await sur la future immédiatement
après avoir appelé la fonction (comme avec alpha(&x).await), ce n'est pas un
problème. Cependant, si on stocke la future ou si on l'envoie à une autre tâche
ou processus, cela peut devenir un problème.
Un contournement courant pour utiliser une async fn avec des références en
argument afin qu'elle retourne une future 'static est d'envelopper à
l'intérieur d'un bloc async les arguments utilisés pour l'appel à la
async fn :
fn incorrect() -> impl Future<Output = u8> {
let x = 5;
emprunter_x(&x) // ERREUR : `x` ne vit pas suffisamment longtemps
}
fn correct() -> impl Future<Output = u8> {
async {
let x = 5;
emprunter_x(&x).await
}
}
En déplaçant l'argument dans le bloc async, nous avons étendu sa durée de vie
à celle de cette Future qui est retournée suite à l'appel à correct.
async move
Les blocs et fermetures asyncautorisent l'utilisation du mot-clé move,
comme les fermetures synchrones. Un bloc async move va prendre possession
des variables qu'il utilise, leur permettant de survivre à l'extérieur de la
portée actuelle, mais par conséquent qui empêche de partager ces variables avec
un autre code :
/// blocs `async` :
///
/// Plusieurs blocs `async` différents peuvent accéder à la même variable
/// locale tant qu'elles sont exécutées dans la portée de la variable
async fn blocs() {
let ma_chaine = "alpha".to_string();
let premiere_future = async {
// ...
println!("{ma_chaine}");
};
let seconde_future = async {
// ...
println!("{ma_chaine}");
};
// Exécute les deux futures jusqu'à leur fin, ce qui affichera
// deux fois "alpha" :
let ((), ()) = futures::join!(premiere_future, seconde_future);
}
/// blocs `async move` :
///
/// Un seul bloc `async move` peut avoir accès à la même variable capturée,
/// puisque qu'elles sont déplacées dans la `Future` générée par le bloc
/// `async move`.
/// Cependant, cela permet d'étendre la portée de la `Future` en dehors de
/// celle de la variable :
fn bloc_avec_move() -> impl Future<Output = ()> {
let ma_chaine = "alpha".to_string();
async move {
// ...
println!("{ma_chaine}");
}
}
Utiliser await avec un exécuteur multi-processus
Remarquez que lorsque vous utilisez un exécuteur de Future multi-processus,
une Future peut être déplacée entre les processus, donc toutes les variables
utilisées dans les corps des async doivent pouvoir aussi être déplacés entre
des processus, car n'importe quel await peut potentiellement basculer sur un
autre processus.
Cela signifie que ce n'est sûr d'utiliser Rc, &RefCell ou tout autre type
qui n'implémente pas le trait Send, y compris les références à des types qui
n'implémente pas le trait Sync.
(Remarque : il reste possible d'utiliser ces types du moment qu'ils ne sont pas
dans la portée d'un appel à await)
Pour la même raison, ce n'est pas une bonne idée de maintenir un verrou
traditionnel, qui ne se préoccupe pas des futures, dans un await, car cela
peut provoquer le blocage du groupe de processus : une tâche peut poser le
verrou, attendre grâce à await et transférer le contrôle à l'exécuteur, qui
va permettre à une autre tâche de vouloir poser le verrou et cela va causer un
interblocage. Pour éviter cela, utilisez le Mutex dans futures::lock plutôt
que celui dans std::sync.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
L'épinglage
Pour piloter les futures, ils doivent être épinglés en utilisant un type
spécial qui s'appelle Pin<T>. Si vous lisez l'explication du trait
Future dans la section précédente, vous devriez constater la présence du Pin dans le
self: Pin<&mut Self> dans la définition de la méthode Future::poll. Mais
qu'est-ce que cela signifie, et pourquoi nous en avons besoin ?
Pourquoi épingler ?
Pin fonctionne en binôme avec le marqueur Unpin. L'épinglage permet de
garantir qu'un objet qui implémente !Unpin ne sera jamais déplacé. Pour
comprendre pourquoi c'est nécessaire, nous devons nous rappeler comment async
et await fonctionnent. Imaginons le code suivant :
let premiere_future = /* ... */;
let seconde_future = /* ... */;
async move {
premiere_future.await;
seconde_future.await;
}
Sous le capot, cela crée un type anonyme qui implémente Future, ce qui va
fournir une méthode poll qui ressemble à ceci :
// Le type `Future` généré pour notre bloc `async { ... }`
struct FutureAsynchrone {
premiere_future: FutOne,
seconde_future: FutTwo,
etat: Etat,
}
// Liste des états dans lesquels notre bloc `async` peut être
enum Etat {
AttentePremiereFuture,
AttenteSecondeFuture,
Termine,
}
impl Future for FutureAsynchrone {
type Output = ();
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> {
loop {
match self.etat {
Etat::AttentePremiereFuture => match self.premiere_future.poll(..) {
Poll::Ready(()) => self.etat = Etat::AttenteSecondeFuture,
Poll::Pending => return Poll::Pending,
}
Etat::AttenteSecondeFuture => match self.seconde_future.poll(..) {
Poll::Ready(()) => self.etat = Etat::Termine,
Poll::Pending => return Poll::Pending,
}
Etat::Termine => return Poll::Ready(()),
}
}
}
}
Lorsque poll est appelé la première fois, il va appeler premiere_future. Si
premiere_future ne peut pas être complété, FutureAsynchrone::poll va retourner
sa valeur. Les appels futurs à poll vont reprendre où le précédent s'est
arrêté. Ce fonctionnement va continuer jusqu'à ce que la future se termine au
complet.
Cependant, que se passe-t-il si nous avons un bloc async qui utilise des
références ? Par exemple :
async {
let mut x = [0; 128];
let lire_dans_un_tampon = lire_dans_un_tampon(&mut x);
lire_dans_un_tampon.await;
println!("{:?}", x);
}
Quelle structure va donner la compilation ?
struct LireDansTampon<'a> {
tampon: &'a mut [u8], // cela pointe sur le `x` ci-desous
}
struct FutureAsynchrone {
x: [u8; 128],
future_lire_dans_un_tampon: LireDansTampon<'quelle_duree_de_vie?>,
}
Ici, la future LireDansTampon contient une référence vers l'autre champ de
notre structure, x. Cependant, si FutureAsynchrone est déplacée,
l'emplacement de x va aussi être déplacé, ce qui va corrompre le pointeur
stocké dans future_lire_dans_un_tampon.tampon.
L'épinglage des futures à un endroit précis de la mémoire évite ce problème, ce
qui va sécuriser la création de références vers des valeurs dans des blocs
async.
L'épinglage en détail
Essayons de comprendre l'épinglage en utilisant un exemple légèrement plus simple. Le problème que nous allons rencontrer ci-dessous peut se résumer à notre manière de gérer les types auto-référentiels en Rust.
Pour l'instant, notre exemple ressemble à ceci :
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
}
impl Test {
fn new(texte: &str) -> Self {
Test {
a: String::from(texte),
b: std::ptr::null(),
}
}
fn initialiser(&mut self) {
let self_ref: *const String = &self.a;
self.b = self_ref;
}
fn a(&self) -> &str {
&self.a
}
fn b(&self) -> &String {
assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser");
unsafe { &*(self.b) }
}
}
Test propose des méthodes pour obtenir une référence vers la valeur des
champs a et b. Comme b est une référence vers a, nous le stockons comme
un pointeur puisque les règles d'emprunt de Rust ne nous autorisent pas à
définir cette durée de vie. Nous avons désormais ce que l'on appelle une
structure auto-référentielle.
Notre exemple fonctionne bien si nous ne déplaçons aucune de nos données, comme vous pouvez le constater en exécutant cet exemple :
fn main() { let mut test1 = Test::new("test1"); test1.initialiser(); let mut test2 = Test::new("test2"); test2.initialiser(); println!("a: {}, b: {}", test1.a(), test1.b()); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(texte: &str) -> Self { Test { a: String::from(texte), b: std::ptr::null(), } } // We need an `init` method to actually set our self-reference fn initialiser(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser"); unsafe { &*(self.b) } } }
Nous obtenons ce que nous attendions :
a: test1, b: test1
a: test2, b: test2
Voyons maintenant ce qui se passe si nous permutions test1 avec test2 et
ainsi nous déplaçons les données :
fn main() { let mut test1 = Test::new("test1"); test1.initialiser(); let mut test2 = Test::new("test2"); test2.initialiser(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(texte: &str) -> Self { Test { a: String::from(texte), b: std::ptr::null(), } } fn initialiser(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser"); unsafe { &*(self.b) } } }
Naïvement, nous pourrions penser que nous devrions obtenir l'écriture de
déboguage de test1 deux fois comme ceci :
a: test1, b: test1
a: test1, b: test1
Mais à la place, nous avons ceci :
a: test1, b: test1
a: test1, b: test2
Le pointeur vers test2.b pointe toujours vers l'ancien emplacement qui est
maintenant test1. La structure n'est plus auto-référentielle, elle contient
un pointeur vers un champ dans un objet différent. Cela signifie que nous ne
pouvons plus considérer que la durée de vie de test2.b soit toujours liée à
la durée de vie de test2.
Si vous n'êtes pas convaincu, ceci devrait vous convaincre :
fn main() { let mut test1 = Test::new("test1"); test1.initialiser(); let mut test2 = Test::new("test2"); test2.initialiser(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); test1.a = "J'ai complètement changé, désormais !".to_string(); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(texte: &str) -> Self { Test { a: String::from(texte), b: std::ptr::null(), } } fn initialiser(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser"); unsafe { &*(self.b) } } }
Le schéma ci-dessous peut vous aider à voir ce qui se passe :
Figure 1 : avant et après l'échange
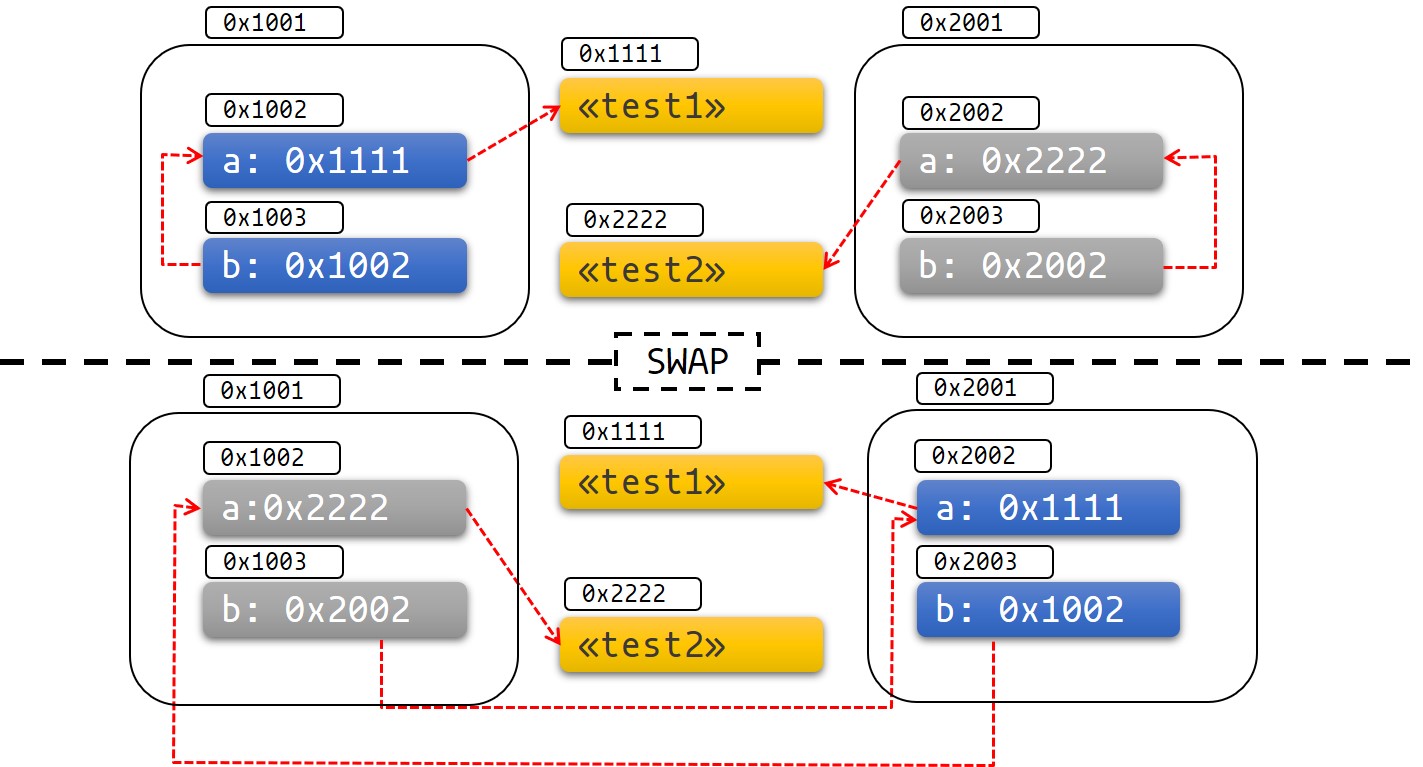
C'est ainsi facile d'avoir un fonctionnement indéfini et aussi de provoquer une autre défaillance spectaculaire.
L'épinglage dans la pratique
Voyons voir comment l'épinglage et le type Pin peut nous aider à résoudre ce
problème.
Le type Pin enveloppe les types de pointeurs, ce qui garantit que les valeurs
derrière ce pointeur ne seront pas déplacées. Par exemple, Pin<&mut T>,
Pin<&T>, Pin<Box<T>> garantissent tous que T ne sera pas déplacé même si
T: !Unpin.
La plupart des types n'ont pas de problème lorsqu'ils sont déplacés. Ces types
implémentent le trait Unpin. Les pointeurs vers des types Unpin peuvent
être librement logés à l'intérieur d'un Pin, ou en être retiré. Par exemple,
u8 implémente Unpin, donc Pin<&mut u8> se comporte exactement comme un
&mut u8 normal.
Cependant, les types qui ne peuvent pas être déplacés après avoir été épinglés
ont un marqueur !Unpin. Les futures créées par async et await en sont un
exemple.
L'épinglage sur la pile
Retournons à notre exemple. Nous pouvons résoudre notre problème en utilisant
Pin. Voyons ce à quoi notre exemple ressemblerait si nous avions utilisé un
pointeur épinglé à la place :
use std::pin::Pin;
use std::marker::PhantomPinned;
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
_marqueur: PhantomPinned,
}
impl Test {
fn new(texte: &str) -> Self {
Test {
a: String::from(texte),
b: std::ptr::null(),
_marqueur: PhantomPinned, // Cela rends notre type `!Unpin`
}
}
fn initialiser(self: Pin<&mut Self>) {
let self_pointeur: *const String = &self.a;
let this = unsafe { self.get_unchecked_mut() };
this.b = self_pointeur;
}
fn a(self: Pin<&Self>) -> &str {
&self.get_ref().a
}
fn b(self: Pin<&Self>) -> &String {
assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser");
unsafe { &*(self.b) }
}
}
L'épinglage d'un objet à la pile va toujours être unsafe si notre type
implémente !Unpin. Vous pouvez utiliser une crate comme
pin_utils pour éviter d'avoir à écrire notre propre unsafe code
lorsqu'on épinglera sur la pile.
Ci-dessous, nous épinglons les objets test1 et test2 sur la pile :
pub fn main() { // test1 peut être déplacé en sécurité avant que nous l'initialisions : let mut test1 = Test::new("test1"); // Notez que nous masquons `test1` pour l'empêcher d'être toujours // accessible : let mut test1 = unsafe { Pin::new_unchecked(&mut test1) }; Test::initialiser(test1.as_mut()); let mut test2 = Test::new("test2"); let mut test2 = unsafe { Pin::new_unchecked(&mut test2) }; Test::initialiser(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); } use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marqueur: PhantomPinned, } impl Test { fn new(texte: &str) -> Self { Test { a: String::from(texte), b: std::ptr::null(), // Cela rends notre type `!Unpin` _marqueur: PhantomPinned, } } fn initialiser(self: Pin<&mut Self>) { let self_pointeur: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_pointeur; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser"); unsafe { &*(self.b) } } }
Maintenant, si nous essayons de déplacer nos données, nous avons désormais une erreur de compilation :
pub fn main() { let mut test1 = Test::new("test1"); let mut test1 = unsafe { Pin::new_unchecked(&mut test1) }; Test::initialiser(test1.as_mut()); let mut test2 = Test::new("test2"); let mut test2 = unsafe { Pin::new_unchecked(&mut test2) }; Test::initialiser(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); std::mem::swap(test1.get_mut(), test2.get_mut()); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); } use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marqueur: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), _marqueur: PhantomPinned, // Cela rends notre type `!Unpin` } } fn initialiser(self: Pin<&mut Self>) { let self_pointeur: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_pointeur; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser"); unsafe { &*(self.b) } } }
Le système de type nous empêche de déplacer les données.
Il est important que vous compreniez que l'épinglage sur la pile s'appuie toujours sur les garanties que vous écrivez dans votre
unsafe. Même si nous savons que ce sur quoi pointe le&'a mut Test épinglé pour la durée de vie de'a, nous ne pouvons pas savoir si la donnée sur laquelle pointe&'a mut Tn'est pas déplacée après que'asoit terminé. Si c'est ce qui se passe, cela violera le contrat duPin.Une erreur courante est d'oublier de masquer la variable originale alors que vous pourriez terminer le
Pinet déplacer la donnée après le&'a mut Tcomme nous le montrons ci-dessous (ce qui viole le contrat duPin) :fn main() { let mut test1 = Test::new("test1"); let mut test1_pin = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1_pin.as_mut()); drop(test1_pin); println!(r#"test1.b pointe sur "test1": {:?}..."#, test1.b); let mut test2 = Test::new("test2"); mem::swap(&mut test1, &mut test2); println!("... et maintenant il pointe nulle part : {:?}", test1.b); } use std::pin::Pin; use std::marker::PhantomPinned; use std::mem; #[derive(Debug)] struct Test { a: String, b: *const String, _marqueur: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), // Cela rends notre type `!Unpin` _marqueur: PhantomPinned, } } fn init<'a>(self: Pin<&'a mut Self>) { let self_pointeur: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_pointeur; } fn a<'a>(self: Pin<&'a Self>) -> &'a str { &self.get_ref().a } fn b<'a>(self: Pin<&'a Self>) -> &'a String { assert!(!self.b.is_null(), "Test::b est appelé sans appeler avant Test::initialiser"); unsafe { &*(self.b) } } }
Epingler sur le tas
L'épinglage d'un type !Unpin sur le tas donne une adresse stable à vos
données donc nous savons que la donnée sur laquelle nous pointons ne peut pas
être déplacée après avoir été épinglée. Contrairement à l'épinglage sur la
pile, nous savons que la donnée va être épinglée pendant la durée de vie de
l'objet.
use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marqueur: PhantomPinned, } impl Test { fn new(texte: &str) -> Pin<Box<Self>> { let t = Test { a: String::from(texte), b: std::ptr::null(), _marqueur: PhantomPinned, }; let mut boxed = Box::pin(t); let self_pointeur: *const String = &boxed.as_ref().a; unsafe { boxed.as_mut().get_unchecked_mut().b = self_pointeur }; boxed } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { unsafe { &*(self.b) } } } pub fn main() { let test1 = Test::new("test1"); let test2 = Test::new("test2"); println!("a: {}, b: {}",test1.as_ref().a(), test1.as_ref().b()); println!("a: {}, b: {}",test2.as_ref().a(), test2.as_ref().b()); }
Certaines fonctions nécessitent que les futures avec lesquelles elles
fonctionnent soient des Unpin. Pour utiliser une Future ou un Stream qui
n'est pas Unpin avec une fonction qui nécessite des types Unpin, vous devez
d'abord épingler la valeur en utilisant soit Box::pin (pour créer un
Pin<Box<T>>) ou la macro pin_utils::pin_mut! (pour créer une
Pin<&mut T>). Pin<Box<Future>> et Pin<&mut Future> peuvent tous deux être
utilisés comme des Futures, et les deux implémentent Unpin.
Par exemple :
use pin_utils::pin_mut; // `pin_utils` est une crate bien pratique,
// disponible sur crates.io
// Une fonction qui prend en argument une `Future` qui implémente `Unpin`.
fn executer_une_future_unpin(x: impl Future<Output = ()> + Unpin) { /* ... */ }
let future = async { /* ... */ };
executer_une_future_unpin(future); // Erreur : `future` n'implémente pas
// le trait `Unpin`
// Epingler avec `Box`:
let future = async { /* ... */ };
let future = Box::pin(future);
executer_une_future_unpin(future); // OK
// Epingler avec `pin_mut!`:
let future = async { /* ... */ };
pin_mut!(future);
executer_une_future_unpin(future); // OK
En résumé
-
Si
T: Unpin(ce qu'il est par défaut), alorsPin<'a, T>est strictement équivalent à&'a mut T. Autrement dit :Unpinsignifie que ce type peut être déplacé sans problème même lorsqu'il est épinglé, doncPinn'aura pas d'impact sur ce genre de type. -
Obtenir un
&mut Tà partir d'un T épinglé nécessite du code non sécurisé siT: !Unpin. -
La plupart des bibliothèques standard implémentent
Unpin. C'est la même chose pour la plupart des types "normaux" que vous utilisez en Rust. UneFuturegénérée parasyncetawaitest une exception à cette généralité. -
Vous pouvez ajouter un lien
!Unpinsur un type avec la version expérimentale de Rust avec un drapeau de fonctionnalité, ou en ajoutant lestd::marker::PhantomPinnedsur votre type avec la version stable. -
Vous pouvez épingler des données soit sur la pile, soit sur le tas.
-
Epingler un objet
!Unpinsur la pile nécessiteunsafe -
Epingler un objet
!Unpinsur le tas ne nécessite pasunsafe. Il existe un raccourci pour faire ceci avecBox::pin. -
Pour les données épinglées où
T: !Unpin, vous devez maintenir l'invariant dont sa mémoire n'est pas invalidée ou réaffectée à partir du moment où elle est épinglée jusqu'à l'appel à drop. C'est une partie très importante du contrat d'épinglage.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
Le trait Stream
Le trait Stream ressemble à Future, mais peut retourner plusieurs valeurs
avant de se terminer, un peu comme le trait Iterator de la bibliothèque
standard :
trait Stream {
/// Le type de la valeur retournée par le flux.
type Item;
/// Tente de résoudre l'élément suivant dans le flux.
/// Retourne :
/// `Poll::Pending` s'il n'est pas encore prêt,
/// `Poll::Ready(Some(x))` si une valeur est prête,
/// `Poll::Ready(None)` si le flux est terminé.
fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>)
-> Poll<Option<Self::Item>>;
}
Un exemple courant d'un Stream est le Receiver pour le type channel de la
crate futures. Cela va retourner Some(val) à chaque fois qu'une valeur est
envoyée par l'extrémité Sender, et va retourner None une fois que Sender
a été libéré de la mémoire et que tous les messages en cours ont été reçus :
async fn send_recv() {
const BUFFER_SIZE: usize = 10;
let (mut tx, mut rx) = mpsc::channel::<i32>(BUFFER_SIZE);
tx.send(1).await.unwrap();
tx.send(2).await.unwrap();
drop(tx);
// `StreamExt::next` ressemble à `Iterator::next`, mais retourne un type
// qui implémente `Future<Output = Option<T>>`.
assert_eq!(Some(1), rx.next().await);
assert_eq!(Some(2), rx.next().await);
assert_eq!(None, rx.next().await);
}
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
L'itération et la concurrence
Comme pour les Iterators synchrones, il existe de nombreuses façons pour
itérer sur les valeurs dans un Stream et pour les traiter. Il existe des
méthodes conçues pour se combiner, comme map, filter et fold, et leurs
cousines conçues pour s'arrêter dès qu'elles rencontrent une erreur, comme
try_map, try_filter, et try_fold.
Malheureusement, les boucles for ne sont pas utilisables avec les Stream,
mais du code plus impératif peut être utilisé, comme while let et les
fonctions next et try_next :
async fn somme_avec_next(mut stream: Pin<&mut dyn Stream<Item = i32>>) -> i32 {
use futures::stream::StreamExt; // pour utiliser `next`
let mut somme = 0;
while let Some(valeur) = stream.next().await {
somme += valeur;
}
somme
}
async fn somme_avec_try_next(
mut stream: Pin<&mut dyn Stream<Item = Result<i32, io::Error>>>,
) -> Result<i32, io::Error> {
use futures::stream::TryStreamExt; // pour utiliser `try_next`
let mut somme = 0;
while let Some(valeur) = stream.try_next().await? {
somme += valeur;
}
Ok(somme)
}
Cependant, si nous ne traitions qu'un seul élément à la fois, nous aurions
probablement gaspillé des occasions de concurrence, ce qui, après tout, est
la raison principale pour laquelle nous écrivons du code asynchrone. Pour
traiter en concurrence plusieurs éléments d'un Stream, utilisez les méthodes
for_each_concurrent et try_for_each_concurrent :
async fn sauter_partout(
mut stream: Pin<&mut dyn Stream<Item = Result<u8, io::Error>>>,
) -> Result<(), io::Error> {
use futures::stream::TryStreamExt; // pour utiliser `try_for_each_concurrent`
const SAUTS_CONCURRENTS_MAXI: usize = 100;
stream.try_for_each_concurrent(SAUTS_CONCURRENTS_MAXI, |nombre| async move {
saute_x_fois(nombre).await?;
reporter_x_sauts(nombre).await?;
Ok(())
}).await?;
Ok(())
}
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
Exécuter plusieurs futures en même temps
Jusqu'à présent, nous avons principalement exécuté les futures en utilisant
.await, ce qui bloque la tâche courante jusqu'à ce qu'une Future soit
terminée. Cependant, les applications asynchrones de la vraie vie ont souvent
besoin d'exécuter plusieurs opérations différentes en concurrence.
Dans ce chapitre, nous allons voir différentes manières d'exécuter plusieurs opérations asynchrones en même temps :
join!: attends que toutes les futures se terminentselect!: attends qu'une des futures se termine- Spawning : crée une tâche de haut-niveau qui exécute de manière globale une future jusqu'à ce qu'elle se termine
FuturesUnordered: un groupe de futures qui retourne le résultat de chaque sous-futures
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
join!
La macro futures::join permet d'attendre que plusieurs futures différentes se
terminent pendant qu'elles sont toutes exécutées en concurrence.
join!
Lorsque nous avons besoin de faire plusieurs opérations asynchrones, il peut
être tentant d'utiliser .await en série sur elles :
async fn obtenir_livre_et_musique() -> (Livre, Musique) {
let livre = obtenir_livre().await;
let musique = obtenir_musique().await;
(livre, musique)
}
En revanche, cela peut être plus lent que nécessaire, puisqu'il ne commence
qu'à obtenir_musique avant que obtenir_livre soit terminé. Dans d'autres
langages, les futures sont exécutées normalement jusqu'à leur fin, donc deux
opérations peuvent être exécutées en concurrence en appelant chacune des
async fn pour démarrer les futures, et ensuite attendre la fin des deux :
// MAUVAISE FAÇON -- ne faites pas cela
async fn obtenir_livre_et_musique() -> (Livre, Musique) {
let future_livre = obtenir_livre();
let future_musique = obtenir_musique();
(future_livre.await, future_musique.await)
}
Malheureusement, les futures en Rust ne font rien tant qu'on n'utilise pas
.await sur elles. Cela signifie que les deux extraits de code ci-dessus vont
exécuter future_livre et future_musique en série au lieu de les exécuter en
concurrence. Pour exécuter correctement les deux futures en concurrence,
utilisons futures::join! :
use futures::join;
async fn obtenir_livre_et_musique() -> (Livre, Musique) {
let future_livre = obtenir_livre();
let future_musique = obtenir_musique();
join!(future_livre, future_musique)
}
La valeur retournée par join! est une tuple contenant le résultat de chacune
des Futures qu'on lui a donné.
try_join!
Pour les futures qui retournent Result, il vaut mieux utiliser try_join!
plutôt que join!. Comme join! se termine uniquement lorsque toutes les
sous-futures se soient terminées, il va continuer à calculer les autres futures
même si une de ses sous-futures a retourné une Err.
Contrairement à join!, try_join! va se terminer tout de suite si une des
sous-futures retourne une erreur.
use futures::try_join;
async fn obtenir_livre() -> Result<Livre, String> { /* ... */ Ok(Livre) }
async fn obtenir_musique() -> Result<Musique, String> { /* ... */ Ok(Musique) }
async fn obtenir_livre_et_musique() -> Result<(Livre, Musique), String> {
let future_livre = obtenir_livre();
let future_musique = obtenir_musique();
try_join!(future_livre, future_musique)
}
Notez que les futures envoyées au try_join! doivent toutes avoir le même type
d'erreur. Vous pouvez utiliser les fonctions .map_err(|e| ...) et
.err_into() de futures::future::TryFutureExt pour regrouper les types
d'erreurs :
use futures::{
future::TryFutureExt,
try_join,
};
async fn obtenir_livre() -> Result<Livre, ()> { /* ... */ Ok(Livre) }
async fn obtenir_musique() -> Result<Musique, String> { /* ... */ Ok(Musique) }
async fn obtenir_livre_et_musique() -> Result<(Livre, Musique), String> {
let future_livre = obtenir_livre().map_err(|()| "Impossible d'obtenir le livre".to_string());
let future_musique = obtenir_musique();
try_join!(future_livre, future_musique)
}
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
select!
La macro futures::select exécute plusieurs futures en même temps, permettant
à son utilisateur de répondre dès qu'une future est terminée.
#![allow(unused)] fn main() { use futures::{ future::FutureExt, // pour utiliser `.fuse()` pin_mut, select, }; async fn premiere_tache() { /* ... */ } async fn seconde_tache() { /* ... */ } async fn course_de_taches() { let t1 = premiere_tache().fuse(); let t2 = seconde_tache().fuse(); pin_mut!(t1, t2); select! { () = t1 => println!("la première tâche s'est terminée en premier"), () = t2 => println!("la seconde tâche s'est terminée en premier"), } } }
La fonction ci-dessus va exécuter t1 et t2 en concurrence. Lorsque t1 ou
t2 se termine, la branche correspondante va appeler println! et la fonction
va se terminer sans terminer la tâche restante.
La syntaxe classique pour select est <motif> = <expression> => <code>,,
répétée par autant de futures que vous voulez gérer avec le select.
default => ... et complete => ...
select autorise aussi l'utilisation des branches default et complete.
La branche default va s'exécuter si aucune des futures dans le select n'est
terminée. Un select avec une branche default toutefois retourner sa valeur
immédiatement, puisque default sera exécuté si aucune des futures n'est
terminée.
La branche complete peut être utilisée pour gérer le cas où toutes les
futures présentes dans le select se sont terminées et ne vont pas plus
progresser. C'est parfois utile lorsqu'on boucle sur un select!.
#![allow(unused)] fn main() { use futures::{future, select}; async fn compter() { let mut future_a = future::ready(4); let mut future_b = future::ready(6); let mut total = 0; loop { select! { a = future_a => total += a, b = future_b => total += b, complete => break, default => unreachable!(), // ne sera jamais exécuté (les futures // sont prêtes, puis ensuite terminées) }; } assert_eq!(total, 10); } }
Utilisation avec Unpin et FusedFuture
Vous avez peut-être remarqué dans le premier exemple ci-dessus que nous avons
dû appeller .fuse() sur les futures retournées par les deux fonctions
asynchrones, ainsi que les épingler avec pin_mut. Chacun de ces appels sont
nécessaires car les futures utilisées dans select doivent implémenter les
traits Unpin et FusedFuture.
Unpin est nécessaire car les futures utilisées par select ne sont pas des
valeurs, mais des références mutables. En évitant de prendre possession de la
future, les futures non terminées peuvent toujours être utilisées après l'appel
à select.
De la même manière, le trait FusedFuture est nécessaire car select ne doit
pas appeler une future après qu'elle soit complétée. FusedFuture est
implémentée par les futures qui ont besoin de savoir si oui ou non elles se
sont terminées. Cela permet d'utiliser select dans une boucle, pour appeler
uniquement les futures qui n'ont pas encore terminé. Nous pouvons voir cela
dans l'exemple ci-dessus, où future_a ou future_b sont terminés dans le
deuxième tour de boucle. Comme la future retournée par future::ready
implémente FusedFuture, c'est possible d'indiquer au select de ne pas les
appeler à nouveau.
Remarquez que les Streams ont un trait FusedStream correspondant. Les
Streams qui implémentent ce trait ou qui ont été enveloppés en utilisant
.fuse() vont produire des futures FusedFutures à partir de leurs
combinateurs .next() ou try_next().
#![allow(unused)] fn main() { use futures::{ select, stream::{FusedStream, Stream, StreamExt}, }; async fn ajouter_deux_streams( mut s1: impl Stream<Item = u8> + FusedStream + Unpin, mut s2: impl Stream<Item = u8> + FusedStream + Unpin, ) -> u8 { let mut total = 0; loop { let element = select! { x = s1.next() => x, x = s2.next() => x, complete => break, }; if let Some(nombre_suivant) = element { total += nombre_suivant; } } total } }
Des tâches concurrentes dans une boucle select avec Fuse et FuturesUnordered
Une fonction difficile à aborder, mais qui est pratique, est
Fuse::terminated(), ce qui permet de construire une future vide qui est déjà
terminée, et qui peut être rempli plus tard avec une future qui a besoin d'être
exécutée.
Cela s'avère utile lorsqu'une tâche nécessite d'être exécuté dans une boucle
select qui est elle-même créée dans la boucle select.
Remarquez l'utilisation de la fonction .select_next_some(). Elle peut être
utilisée avec select pour exécuter uniquement la branche pour les valeurs
Some(_) retournées par le Stream, en ignorant les Nones.
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, pin_mut, select, stream::{FusedStream, Stream, StreamExt}, }; async fn obtenir_nouveau_nombre() -> u8 { /* ... */ 5 } async fn executer_avec_nouveau_nombre(_: u8) { /* ... */ } async fn executer_boucle( mut temporisation: impl Stream<Item = ()> + FusedStream + Unpin, nombre_initial: u8, ) { let executer_avec_nouveau_nombre_future = executer_avec_nouveau_nombre(nombre_initial).fuse(); let obtenir_nouveau_nombre_future = Fuse::terminated(); pin_mut!( executer_avec_nouveau_nombre_future, obtenir_nouveau_nombre_future ); loop { select! { () = temporisation.select_next_some() => { // La temporisation s'est terminée. Démarre un nouveau // `obtenir_nouveau_nombre_future` s'il n'y en a pas un qui est // déjà en cours d'exécution. if obtenir_nouveau_nombre_future.is_terminated() { obtenir_nouveau_nombre_future.set(obtenir_nouveau_nombre().fuse()); } }, new_num = obtenir_nouveau_nombre_future => { // Un nouveau nombre est arrivé : cela démarrera un nouveau // `executer_avec_nouveau_nombre_future`, ce qui libèrera // l'ancien. executer_avec_nouveau_nombre_future.set(executer_avec_nouveau_nombre(new_num).fuse()); }, // Execute le `executer_avec_nouveau_nombre_future` () = executer_avec_nouveau_nombre_future => {}, // panique si tout est terminé, car la `temporisation` est censé // générer des valeurs à l'infini. complete => panic!("`temporisation` s'est terminé inopinément"), } } } }
Lorsque de nombreuses copies d'une même future a besoin d'être exécuté en même
temps, utilisez le type FuturesUnordered. L'exemple suivant ressemble à celui
ci-dessus, mais va exécuter chaque copie de obtenir_nouveau_nombre_future
jusqu'à ce qu'elles soient terminées, plutôt que de les arrêter lorsqu'une
nouvelle est générée. Cela va aussi afficher la valeur retournée par
obtenir_nouveau_nombre_future.
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, pin_mut, select, stream::{FusedStream, FuturesUnordered, Stream, StreamExt}, }; async fn obtenir_nouveau_nombre() -> u8 { /* ... */ 5 } async fn executer_avec_nouveau_nombre(_: u8) -> u8 { /* ... */ 5 } // Exécute `executer_avec_nouveau_nombre` avec le dernier nombre obtenu // auprès de `obtenir_nouveau_nombre`. // // `obtenir_nouveau_nombre` est exécuté à nouveau à chaque fois que la // temporisation se termine, ce qui annule immédiatement le // `executer_avec_nouveau_nombre` en cours et la remplace avec la nouvelle // valeur retournée. async fn executer_boucle( mut temporisation: impl Stream<Item = ()> + FusedStream + Unpin, nombre_initial: u8, ) { let mut executer_avec_nouveau_nombre_futures = FuturesUnordered::new(); executer_avec_nouveau_nombre_futures.push(executer_avec_nouveau_nombre(nombre_initial)); let obtenir_nouveau_nombre_future = Fuse::terminated(); pin_mut!(obtenir_nouveau_nombre_future); loop { select! { () = temporisation.select_next_some() => { // La temporisation s'est terminée. Démarre un nouveau // `obtenir_nouveau_nombre_future` s'il n'y en a pas un qui est // déjà en cours d'exécution. if obtenir_nouveau_nombre_future.is_terminated() { obtenir_nouveau_nombre_future.set(obtenir_nouveau_nombre().fuse()); } }, new_num = obtenir_nouveau_nombre_future => { // Un nouveau nombre est arrivé : cela démarrera un nouveau // `executer_avec_nouveau_nombre_future`.. executer_avec_nouveau_nombre_futures.push(executer_avec_nouveau_nombre(new_num)); }, // Exécute le `executer_avec_nouveau_nombre_futures` et vérifie si certaines ont terminé. res = executer_avec_nouveau_nombre_futures.select_next_some() => { println!("executer_avec_nouveau_nombre_future a retourné {:?}", res); }, // panique si tout est terminé, car la `temporisation` est censé // générer des valeurs à l'infini. complete => panic!("`temporisation` s'est terminé inopinément"), } } } }
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
Solutions de contournement à connaître et à utiliser
La prise en charge de async en Rust est relativement nouvelle, et certaines
fonctionnalités très demandées sont toujours en cours de développement, et
certaines solutions de diagnostic laissent à désirer. Ce chapitre va
présenter certaines situations délicates et expliquer comment les contourner.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Vous pouvez contribuer à l'amélioration de cette page sur sa Pull Request.
? dans les blocs async
Tout comme dans async fn, il est courant d'utiliser ? dans des blocs
async. Cependant, le type de retour des blocs async n'a pas d'état
explicite. Cela peut faire échouer le compilateur à déduire le type d'erreur du
bloc async.
Par exemple, ce code ...
#![allow(unused)] fn main() { struct MonErreur; async fn alpha() -> Result<(), MonErreur> { Ok(()) } async fn beta() -> Result<(), MonErreur> { Ok(()) } let future = async { alpha().await?; beta().await?; Ok(()) }; }
... va déclencher cette erreur :
error[E0282]: type annotations needed
-- > src/main.rs:5:9
|
4 | let future = async {
| ------ consider giving `fut` a type
5 | alpha().await?;
| ^^^^^^^^^^^^^^ cannot infer type
Malheureusement, il n'existe pas pour l'instant de façon de "donner un type à
future", ni une manière pour préciser explicitement le type de retour d'un
bloc async.
Pour contourner cela, utilisez l'opérateur "turbofish" pour renseigner les
types de succès et d'erreur pour le bloc async :
#![allow(unused)] fn main() { struct MonErreur; async fn alpha() -> Result<(), MonErreur> { Ok(()) } async fn beta() -> Result<(), MonErreur> { Ok(()) } let future = async { alpha().await?; beta().await?; Ok::<(), MonErreur>(()) // <- remarquez l'annotation de type explicite ici }; }
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
L'approximation de Send
Certaines machines à état de fonctions asynchrones sont sûres pour être
envoyées entre des processus, alors que d'autres ne le sont pas. Le fait que la
Future d'une fonction asynchrone est Send ou non est conditionné par le
fait qu'un type Send soit maintenu par un .await, mais cette approche est
aujourd'hui trop conservatrice sur certains points.
Par exemple, imaginez un simple type qui n'est pas Send, comme un type qui
contient un Rc :
#![allow(unused)] fn main() { use std::rc::Rc; #[derive(Default)] struct EstPasSend(Rc<()>); }
Les variables du type EstPasSend peuvent intervenir brièvement dans des
fonctions asynchrones même si le type résultant de la Future retournée par la
fonction asynchrone doit être Send :
use std::rc::Rc; #[derive(Default)] struct EstPasSend(Rc<()>); async fn beta() {} async fn alpha() { EstPasSend::default(); beta().await; } fn necessite_send(_: impl Send) {} fn main() { necessite_send(alpha()); }
Cependant, si nous changeons alpha pour stocker le EstPasSend dans une
variable, cet exemple ne se compile plus :
use std::rc::Rc; #[derive(Default)] struct EstPasSend(Rc<()>); async fn beta() {} async fn alpha() { let x = EstPasSend::default(); beta().await; } fn necessite_send(_: impl Send) {} fn main() { necessite_send(alpha()); }
error[E0277]: `std::rc::Rc<()>` cannot be sent between threads safely
-- > src/main.rs:15:5
|
15 | necessite_send(foo());
| ^^^^^^^^^^^^^^ `std::rc::Rc<()>` cannot be sent between threads safely
|
= help: within `impl std::future::Future`, the trait `std::marker::Send` is not implemented for `std::rc::Rc<()>`
= note: required because it appears within the type `EstPasSend`
= note: required because it appears within the type `{EstPasSend, impl std::future::Future, ()}`
= note: required because it appears within the type `[static generator@src/main.rs:7:16: 10:2 {EstPasSend, impl std::future::Future, ()}]`
= note: required because it appears within the type `std::future::GenFuture<[static generator@src/main.rs:7:16: 10:2 {EstPasSend, impl std::future::Future, ()}]>`
= note: required because it appears within the type `impl std::future::Future`
= note: required because it appears within the type `impl std::future::Future`
note: required by `necessite_send`
-- > src/main.rs:12:1
|
12 | fn necessite_send(_: impl Send) {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0277`.
Cette erreur est justifiée. Si nous stockons x dans une variable, il ne sera
pas libéré avant d'arriver après le .await, moment où la fonction asynchrone
s'exécute peut-être sur un processus différent. Comme Rc n'est pas Send,
lui permettre de voyager entre les processus ne serait pas sain. Une solution
simple à cela serait de libérer le Rc avec drop avant le .await, mais
malheureusement cela ne fonctionne pas aujourd'hui.
Pour contourner ce problème, vous pouvez créer une portée de bloc qui englobe
chacune des variables qui ne sont pas Send. Cela permet de dire facilement au
compilateur que ces variables ne vivent plus en dehors de l'utilisation du
.await.
use std::rc::Rc; #[derive(Default)] struct EstPasSend(Rc<()>); async fn beta() {} async fn alpha() { { let x = EstPasSend::default(); } beta().await; } fn necessite_send(_: impl Send) {} fn main() { necessite_send(alpha()); }
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
La récursivité
En interne, une fonction asynchrone génère une machine à états qui contient
chaque sous-future qui sont attendus avec await. Cela rend la récursivité des
fonctions asynchrones un peu compliqué, car la machine à état doit se contenir
elle-même :
#![allow(unused)] fn main() { async fn etape_une() { /* ... */ } async fn etape_deux() { /* ... */ } struct EtapeUne; struct EtapeDeux; // Cette fonction ... async fn alpha() { etape_une().await; etape_deux().await; } // ... génère un type comme celui-ci : enum Alpha { Premiere(EtapeUne), Seconde(EtapeDeux), } // Donc cette fonction ... async fn recursif() { recursif().await; recursif().await; } // ... génère un type comme celui-ci : enum Recursif { Premiere(Recursif), Seconde(Recursif), } }
Cela ne fonctionne pas, nous avons créé un type de taille infinie ! Le compilateur va se plaindre :
error[E0733]: recursion in an `async fn` requires boxing
-- > src/lib.rs:1:22
|
1 | async fn recursif() {
| ^ an `async fn` cannot invoke itself directly
|
= note: a recursive `async fn` must be rewritten to return a boxed future.
Pour nous permettre cela, nous devons faire une dérivation en utilisant
Box. Malheureusement, les limitations du compilateur font en sorte
qu'envelopper les appels à recursif() dans une Box::pin n'est pas
suffisant. Pour que cela fonctionne, nous devons transformer recursif en
fonction synchrone pour retourner un bloc async qui est dans une Box :
#![allow(unused)] fn main() { use futures::future::{BoxFuture, FutureExt}; fn recursif() -> BoxFuture<'static, ()> { async move { recursif().await; recursif().await; }.boxed() } }
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
async dans les traits
Actuellement, les fonctions asynchrones ne peuvent pas être utilisées dans les traits. Les raisons à cela sont un peu complexes, mais il a des solutions en préparation pour lever cette restriction à l'avenir.
Cependant, cette restriction peut être contournée en utilisant la crate async-trait à partir de crates.io.
Notez toutefois que l'utilisation de ces méthodes de trait vont provoquer des allocations sur le tas à chaque appel de fonction. Cela n'a pas d'impact significatif sur la grande majorité des applications, mais cela doit être pris en compte lorsqu'on décide d'utiliser cette fonctionnalité dans l'API publique d'une fonction bas-niveau qui peut être appelé des millions de fois par seconde.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
L'écosystème asynchrone
Actuellement, Rust ne fournit que l'essentiel pour écrire du code asynchrone. En particulier, les exécuteurs, les tâches, les réacteurs, les combinateurs, et les futures et les traits de bas-niveau d'entrée/sortie ne sont pas encore fournis par la bibliothèque standard. Mais en attendant, les écosystèmes asynchrones fournis par la communauté répondent à ce besoin.
L'équipe en charge des fondations de l'asynchrone est intéressée par le développement dans le livre sur l'asynchrone pour couvrir plusieurs environnements d'exécution. Si vous êtes intéressé pour contribuer à ce projet, veuillez vous rendre sur Zulip.
Les environnements d'exécution asynchrone
Les environnements d'exécution asynchrones sont des bibliothèques utilisées pour exécuter des applications asynchrones. Les environnements d'exécution embarquent généralement ensemble un réacteur avec un ou plusieurs exécuteurs. Les réacteurs fournissent des mécanismes d'abonnement pour les évènements externes, comme les entrées/sorties asynchrones, la communication entre les processus, et les temporisations. Dans un environnement d'exécution asynchrone, les abonnés sont typiquement des futures qui représentent les opérations d'entrées/sorties de bas-niveau. Les exécuteurs gèrent la planification et l'exécution des tâches. Ils assurent le suivi les tâches en cours d'exécution et celles qui sont suspendues, l'appel des futures jusqu'à ce qu'elles terminent, et réaniment les tâches lorsqu'elles peuvent progresser. Le mot "exécuteur" est souvent permuté avec "l'environnement d'exécution". Ici, nous utilisons le mot "écosystème" pour décrire un environnement d'exécution accompagné des traits et fonctionnalités compatibles.
Les crates asynchrones fournies par la communauté
La crate Futures
La crate futures contient les traits et les
fonctions utiles pour écrire du code asynchrone. Cela comprend les traits
Stream, Sink, AsyncRead, et AsyncWrite, et des utilitaires comme les
combinateurs. Ces utilitaires et ces traits pourraient éventuellement faire
partie un jour de la bibliothèque standard.
Les futures ont leur propre exécuteur, mais pas son propre réacteur, donc
cela ne prend pas en charge l'exécution d'entrées/sorties asynchrones ou de
futures de temporisation. C'est pour cette raison que ce n'est pas considéré
comme un environnement d'exécution complet.
Il est courant d'employer les utilitaires de futures avec un exécuteur d'une
autre crate.
Les environnements d'exécution asynchrones populaires
Il n'y a pas d'environnement d'exécution asynchrone dans la bibliothèque standard, et aucune n'est officiellement recommandée. Les crates suivantes offrent des environnement d'exécution populaires.
- Tokio : un écosystème asynchrone populaire pour des cadriciels travaillant avec HTTP, gRPC et du traçage.
- async-std : une crate qui fournit des équivalents asynchrones aux composants de la bibliothèque standard.
- smol : un environnement d'exécution asynchrone, minimisé et simplifié.
La compatibilité des écosystèmes
Toutes les applications, cadriciels, et bibliothèques asynchrones ne sont pas compatibles entre elles, ou avec tous les systèmes d'exploitation ou plateformes. La plupart du code asynchrone peut être utilisé avec n'importe quel écosystème, mais certains cadriciels et bibliothèques nécessitent l'utilisation d'un écosystème précis. Les contraintes d'un écosystème ne sont pas toujours documentées, mais quelques méthodes empiriques pour déterminer si une bibliothèque, un trait, ou une fonction dépends d'un écosystème précis.
Tout code asynchrone qui interagit avec des entrées/sorties, temporisations,
communication inter-processus, ou des tâches asynchrones dépend généralement
d'un exécuteur ou réacteur asynchrone.
Tous les autres codes asynchrones, comme les expressions, combinateurs, types
de sychronisation, et les Stream asynchrones sont généralement indépendants
des écosystèmes, à condition que toutes les futures imbriquées sont aussi
indépendantes de tout écosystème.
Avant de commencer un projet, il est recommandé de rechercher les cadriciels
et bibliothèques asynchrones que vous aurez besoin pour vous assurer la
compatibilité entre eux et avec l'environnement d'exécution que vous avez
choisi.
En particulier, Tokio utilise le réacteur mio et définit ses propres
versions des traits d'entrées/sorties asynchrones, y compris AsyncRead et
AsyncWrite. Seul, il n'est pas compatible avec async-std et smol, qui
reposent sur la crate async-executor, et
les traits AsyncRead et AsyncWrite sont définis dans futures.
Les pré-requis d'environnement d'exécution en conflit peuvent parfois être
résolus avec des couches de compatibilité qui vous permettent d'appeler du code
écrit pour un environnement d'exécution dans un autre.
Par exemple, la crate async_compat fournit
une couche de compatibilité entre Tokio et les autres environnements
d'exécution.
Les bibliothèques qui exposent des APIs asynchrones ne devraient pas dépendre d'un exécuteur ou d'un réacteur en particulier, à moins qu'ils aient besoin de créer des tâches ou de définir leurs propres entrées/sorties asynchrones ou des futures de temporisation. Dans l'idéal, seuls les binaires devraient être responsables de la planification et de l'exécution des tâches.
Les exécuteurs mono-processus versus multi-processus
Les exécuteurs asynchrones peuvent être mono-processus ou multi-processus.
Par exemple, la crate async-executor a deux LocalExecutor mono-processus et
un Executor multi-processus.
Les exécuteurs multi-processus permettent de faire progresser plusieurs tâches en simultané. Cela peut accélérer considérablement l'exécution pour les charges de travail avec beaucoup de tâches, mais la synchronisation des données entre les tâches est habituellement moins rentable. Il est recommandé de mesurer les performances de votre application lorsque vous choisissez entre un environnement d'exécution mono-processus et multi-processus.
Les tâches peuvent être exécutées soit sur le processus qui les a créés, ou sur
processus séparé. Les environnements d'exécution asynchrones fournissent
souvent des fonctionnalités pour créer des tâches sur des processus séparés.
Même si les tâches sont exécutées sur des processus séparés, ils ne doivent
toujours pas être bloquants. Pour pouvoir planifier l'exécution des tâches sur
un exécuteur multi-processus, elles doivent être aussi être Send. Certains
environnements d'exécution fournissent des fonctions pour créer des tâches qui
ne sont pas Send, ce qui permet de s'assurer que les tâches sont exécutées
sur le processus qui les ont créés.
Ils peuvent également fournir des fonctions pour créer des tâches bloquantes
sur des processus dédiés, ce qui est pratique pour exécuter du code synchrone
bloquant des autres bibliothèques.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Projet final : construire un serveur web concurrent avec le Rust asynchrone
Dans ce chapitre, nous allons utiliser le Rust asynchrone pour modifier le serveur web mono-processus du livre sur Rust, afin qu'il serve les requêtes de manière concurrente.
Résumé
Voici ce à quoi ressemblera le code à la fin de cette leçon.
src/main.rs :
use std::fs; use std::io::prelude::*; use std::net::TcpListener; use std::net::TcpStream; fn main() { // Ecoute les connexions TCP entrantes sur localhost, port 7878. let ecouteur = TcpListener::bind("127.0.0.1:7878").unwrap(); // Bloque pour toujours, gérant chaque requête qui arrive // sur cette adresse IP. for flux in ecouteur.incoming() { let flux = flux.unwrap(); gestion_connexion(flux); } } fn gestion_connexion(mut flux: TcpStream) { // Lit les 1024 premiers octets de données présents dans le flux let mut tampon = [0; 1024]; flux.read(&mut tampon).unwrap(); let get = b"GET / HTTP/1.1\r\n"; // Répond avec l'accueil ou une erreur 404, // en fonction des données présentes dans la requête let (ligne_statut, nom_fichier) = if tampon.starts_with(get) { ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html") }; let contenu = fs::read_to_string(nom_fichier).unwrap(); // Ecrit la réponse dans le flux, et purge le flux pour s'assurer // que la réponse est bien renvoyée au client let reponse = format!("{ligne_statut}{contenu}"); flux.write_all(reponse.as_bytes()).unwrap(); flux.flush().unwrap(); }
hello.html :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Salutations !</title>
</head>
<body>
<h1>Salut !</h1>
<p>Bonjour de la part de Rust</p>
</body>
</html>
404.html :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Salutations !</title>
</head>
<body>
<h1>Oups !</h1>
<p>Désolé, je ne connaît pas ce que vous demandez.</p>
</body>
</html>
Si vous exécutez le serveur avec cargo run et visitez 127.0.0.1:7878 dans
votre navigateur, vous allez être accueilli par un message chaleureux de
Ferris !
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Exécuter du code asynchrone
Un serveur HTTP doit être capable de servir plusieurs clients en concurrence, et par conséquent, il ne doit pas attendre que les requêtes précédentes soient terminées pour s'occuper de la requête en cours. Le livre Rust résout ce problème en créant un groupe de tâches où chaque connexion est gérée sur son propre processus. Nous allons obtenir le même effet en utilisant du code asynchrone, au lieu d'améliorer le débit en ajoutant des processus.
Modifions le gestion_connexion pour retourner une future en la déclarant
comme étant une fonction asynchrone :
async fn gestion_connexion(mut flux: TcpStream) {
//<-- partie masquée ici -->
}
L'ajout de async à la déclaration de la fonction change son type de retour de
() à un type qui implémente Future<Output=()>.
Si nous essayons de compiler cela, le compilateur va nous avertir que cela ne fonctionnera pas :
$ cargo check
Checking async-rust v0.1.0 (file:///projects/async-rust)
warning: unused implementer of `std::future::Future` that must be used
-- > src/main.rs:12:9
|
12 | gestion_connexion(flux);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: futures do nothing unless you `.await` or poll them
Comme nous n'avons pas utilisé await ou poll sur le résultat de
gestion_connexion, cela ne va jamais s'exécuter. Si vous lancez le serveur et
visitez 127.0.0.1:7878 dans un navigateur web, vous constaterez que la
connexion est refusée, notre serveur ne prend pas en charge les requêtes.
Nous ne pouvons pas utiliser await ou poll sur des futures dans du code
synchrone tout seul.
Nous allons avoir besoin d'un environnement d'exécution asynchrone pour gérer
la planification et l'exécution des futures jusqu'à ce qu'elles se terminent.
Vous pouvez consulter la section pour choisir un environnement
d'exécution pour plus d'information sur les
environnements d'exécution, exécuteurs et réacteurs asynchrones.
Tous les environnements d'exécution listés vont fonctionner pour ce projet,
mais pour ces exemples, nous avons choisi d'utiliser la crate async-std.
Ajouter un environnement d'exécution asynchrone
L'exemple suivant va monter le remaniement du code synchrone pour utiliser un
environnement d'exécution asynchrone, dans ce cas async-std.
L'attribut #[async_std::main] de async-std nous permet d'écrire une
fonction main asynchrone.
Pour l'utiliser, il faut activer la fonctionnalité attributes de async-std
dans Cargo.toml :
[dependencies.async-std]
version = "1.6"
features = ["attributes"]
Pour commencer, nous allons changer pour une fonction main asynchrone, et
utiliser await sur la future retournée par la version asynchrone de
gestion_connexion. Ensuite, nous testerons comment le serveur répond. Voici à
quoi cela ressemblerait :
#[async_std::main] async fn main() { let ecouteur = TcpListener::bind("127.0.0.1:7878").unwrap(); for flux in ecouteur.incoming() { let flux = flux.unwrap(); // Attention : cela n'est pas concurrent ! gestion_connexion(flux).await; } }
Maintenant, testons pour voir si notre serveur peut gérer les connexions en
concurrence. Transformer simplement gestion_connexion en asynchrone ne
signifie pas que le serveur puisse gérer plusieurs connexions en même temps, et
nous allons bientôt voir pourquoi.
Pour illustrer cela, simulons une réponse lente.
Lorsqu'un client fait une requête vers 127.0.0.1:7878/pause, notre serveur va
attendre 5 secondes :
use async_std::task;
async fn gestion_connexion(mut flux: TcpStream) {
let mut tampon = [0; 1024];
flux.read(&mut tampon).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let pause = b"GET /pause HTTP/1.1\r\n";
let (ligne_statut, nom_fichier) = if tampon.starts_with(get) {
("HTTP/1.1 200 OK\r\n\r\n", "hello.html")
} else if tampon.starts_with(pause) {
task::sleep(Duration::from_secs(5)).await;
("HTTP/1.1 200 OK\r\n\r\n", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html")
};
let contenu = fs::read_to_string(nom_fichier).unwrap();
let reponse = format!("{ligne_statut}{contenu}");
flux.write(reponse.as_bytes()).unwrap();
flux.flush().unwrap();
}
C'est très ressemblant à la simulation d'une requête
lente
dans le livre Rust, mais avec une différence importante :
nous utilisons la fonction non bloquante async_std::task::sleep au lieu de la
fonction bloquante std::thread::sleep.
Il est important de se rappeler que même si un code est exécuté dans une
fonction asynchrone et qu'on utilise await sur elle, elle peut toujours
bloquer.
Pour tester si notre serveur puisse gérer les connexions en concurrence, nous
avons besoin de nous assurer que gestion_connexion n'est pas bloquante.
Si vous exécutez le serveur, vous constaterez qu'une requête vers
127.0.0.1:7878/pause devrait bloquer toutes les autres requêtes entrantes
pendant 5 secondes !
C'est parce qu'il n'y a pas d'autres tâches concurrentes qui peuvent progresser
pendant que nous utilisons await sur le résultat de gestion_connexion.
Dans la prochaine section, nous allons voir comment utiliser du code asynchrone
pour gérer en concurrence les connexions.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Gérer les connexions en concurrence
Le problème avec notre code précédent est que ecouteur.incoming() est un
itérateur bloquant. L'exécuteur ne peut pas exécuter d'autres futures pendant
que ecouteur attends les connexions entrantes, et nous ne pouvons pas gérer
une nouvelle connexion jusqu'à ce que nous ayons terminé avec la précédente.
Pour corriger cela, nous allons transformer l'itérateur bloquant
ecouteur.incoming() en Stream non bloquant. Les Streams ressemblent aux
itérateurs, mais peuvent être consommés de manière asynchrone. Pour plus
d'informations, vous pouvez consulter le chapitre sur les
Streams.
Remplaçons notre std::net::TcpListener bloquant par le
async_std::net::TcpListener non bloquant, et mettons à jour notre gestion de
connexion pour accepter un async_std::net::TcpStream :
use async_std::prelude::*;
async fn gestion_connexion(mut flux: TcpStream) {
let mut tampon = [0; 1024];
flux.read(&mut tampon).await.unwrap();
//<-- partie masquée ici -->
flux.write(reponse.as_bytes()).await.unwrap();
flux.flush().await.unwrap();
}
La version asynchrone de TcpListener implémente le trait Stream sur
ecouteur.incoming(), ce qui apporte deux avantages.
Le premier est que ecouteur.incoming() ne bloque plus l'exécuteur.
L'exécuteur peut maintenant transférer l'exécution à d'autres futures en
attente lorsqu'il n'y a plus de connexions TCP entrantes à traiter.
Le second bienfait est que les éléments du Stream peuvent optionnellement
être traités en concurrence, en utilisant la méthode for_each_concurrent des
Streams.
Ici, nous allons profiter de cette méthode pour traiter chaque requête entrante
de manière concurrente.
Nous avons besoin d'importer le trait Stream de la crate futures, donc
notre Cargo.toml ressemble maintenant à ceci :
+[dependencies]
+futures = "0.3"
[dependencies.async-std]
version = "1.6"
features = ["attributes"]
Maintenant, nous pouvons traiter chaque connexion en concurrence en passant
gestion_connexion dans une fermeture. La fermeture prend possession de chaque
TcpStream, et est exécuté dès qu'un nouveau TcpStream est disponible. Tant
que gestion_connexion ne bloque pas, une réponse lente ne va plus empêcher
les autres requêtes de se compléter.
use async_std::net::TcpListener;
use async_std::net::TcpStream;
use futures::stream::StreamExt;
#[async_std::main]
async fn main() {
let ecouteur = TcpListener::bind("127.0.0.1:7878").await.unwrap();
ecouteur
.incoming()
.for_each_concurrent(/* limite */ None, |flux_tcp| async move {
let flux_tcp = flux_tcp.unwrap();
gestion_connexion(flux_tcp).await;
})
.await;
}
Servir les requêtes en parallèle
Notre exemple jusqu'à présent a largement présenté la concurrence (en utilisant
du code asynchrone) comme étant une alternative au parallélisme (en utilisant
des processus).
Cependant, le code asynchrone et les processus ne s'excluent pas mutuellement.
Dans notre exemple, for_each_concurrent traite chaque connexion en
concurrence, mais sur le même processus.
La crate async-std nous permet également de créer des tâches sur des
processus séparés.
Comme gestion_connexion est à la fois Send et non bloquant, il est sûr à
utiliser avec async_std::task::spawn.
Voici à quoi cela devrait ressembler :
use async_std::task::spawn; #[async_std::main] async fn main() { let ecouteur = TcpListener::bind("127.0.0.1:7878").await.unwrap(); ecouteur .incoming() .for_each_concurrent(/* limite */ None, |flux| async move { let flux = flux.unwrap(); spawn(gestion_connexion(flux)); }) .await; }
Maintenant nous utilisons à la fois la concurrence et le parallélisme pour traiter plusieurs requêtes en même temps ! Lisez la section sur les exécuteurs multi-processus pour en savoir plus.
🚧 Attention, peinture fraîche !
Cette page a été traduite par une seule personne et n'a pas été relue et vérifiée par quelqu'un d'autre ! Les informations peuvent par exemple être erronées, être formulées maladroitement, ou contenir d'autres types de fautes.
Test du serveur TCP
Passons désormais au test de notre fonction gestion_connexion.
D'abord, nous avons besoin d'un TcpStream avec lequel travailler.
Dans un test d'intégration ou de bout-à-bout, nous serions tentés de faire une
vraie connexion TCP pour tester notre code.
Une des stratégies pour faire cela est de démarrer un écouteur sur le port 0 de
localhost.
Le port 0 n'est pas un port UNIX valide, mais il fonctionne pour faire des
tests.
Le système d'exploitation va obtenir un port TCP ouvert pour nous.
Dans cet exemple, nous allons plutôt écrire un test unitaire pour le
gestionnaire de connexion, pour vérifier que les réponses correctes soient
retournées à leurs entrées respectives.
Pour faire en sorte que notre test unitaire soit isolé et déterminé, nous
allons remplacer le TcpStream par un mock.
Pour commencer, nous allons changer la signature de gestion_connexion pour
faciliter ses tests.
En fait, gestion_connexion ne nécessite pas de async_std::net::TcpStream,
il a juste besoin d'une structure qui implémente async_std::io::Read,
async_std::io::Write, et marker::Unpin.
Changeons la signature du type dans ce sens nous permet de lui passer un mock
pour la tester.
use std::marker::Unpin;
use async_std::io::{Read, Write};
async fn gestion_connexion(mut stream: impl Read + Write + Unpin) {
Ensuite, créons un mock de TcpStream qui implémente ces traits.
Implémentons d'abord le trait Read, qui a une méthode, poll_read.
Notre mock de TcpStream va contenir certaines données qui sont copiées dans
le tampon de lecture, et nous allons retourner Poll::Ready pour signaler que
la lecture est terminée.
use super::*;
use futures::io::Error;
use futures::task::{Context, Poll};
use std::cmp::min;
use std::pin::Pin;
struct MockTcpStream {
donnees_lecture: Vec<u8>,
donnees_ecriture: Vec<u8>,
}
impl Read for MockTcpStream {
fn poll_read(
self: Pin<&mut Self>,
_: &mut Context,
tampon: &mut [u8],
) -> Poll<Result<usize, Error>> {
let taille: usize = min(self.donnees_lecture.len(), tampon.len());
tampon[..taille].copy_from_slice(&self.donnees_lecture[..taille]);
Poll::Ready(Ok(taille))
}
}
Notre implémentation de Write y ressemble beaucoup, même si nous avons besoin
d'écrire trois méthodes : poll_write, poll_flush, et poll_close.
poll_write va copier toutes les données d'entrée dans le mock de TcpStream,
et retourne Poll::Ready lorsqu'elle sera terminée.
Il n'y a pas besoin de purger et fermer le mock de TcpStream, donc
poll_flush et poll_close peuvent simplement retourner Poll::Ready.
impl Write for MockTcpStream {
fn poll_write(
mut self: Pin<&mut Self>,
_: &mut Context,
tampon: &[u8],
) -> Poll<Result<usize, Error>> {
self.donnees_ecriture = Vec::from(tampon);
Poll::Ready(Ok(tampon.len()))
}
fn poll_flush(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> {
Poll::Ready(Ok(()))
}
fn poll_close(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> {
Poll::Ready(Ok(()))
}
}
Enfin, notre mock a besoin d'implémenter Unpin, ce qui veut dire que sa
position dans la mémoire peut être déplacée en toute sécurité. Pour plus
d'informations sur l'épinglage et le trait Unpin, rendez-vous à la section
sur l'épinglage.
use std::marker::Unpin;
impl Unpin for MockTcpStream {}
Maintenant nous sommes prêts à tester la fonction gestion_connexion.
Après avoir réglé le MockTcpStream pour contenir les données initiales, nous
pouvons exécuter gestion_connexion en utilisant l'attribut
#[async_std::test], de la même manière que nous avons utilisé
#[async_std::main].
Pour nous assurer que gestion_connexion fonctionne comme attendu, nous
allons vérifier que les données ont été correctement écrites dans le
MockTcpStream en fonction de son contenu initial.
use std::fs;
#[async_std::test]
async fn test_gestion_connexion() {
let octets_entree = b"GET / HTTP/1.1\r\n";
let mut contenu = vec![0u8; 1024];
contenu[..octets_entree.len()].clone_from_slice(octets_entree);
let mut flux = MockTcpStream {
donnees_lecture: contenu,
donnees_ecriture: Vec::new(),
};
gestion_connexion(&mut flux).await;
let mut tampon = [0u8; 1024];
flux.read(&mut tampon).await.unwrap();
let contenu_attendu = fs::read_to_string("hello.html").unwrap();
let reponse_attendue = format!("HTTP/1.1 200 OK\r\n\r\n{}", contenu_attendu);
assert!(flux.donnees_ecriture.starts_with(reponse_attendue.as_bytes()));
}
Annexe : traductions du livre
Pour plus d'informations dans d'autres langues que le Français.
Traduction des termes
Voici les principaux termes techniques qui ont été traduits de l'anglais vers le français.
| Anglais | Français | Remarques |
|---|---|---|
| actor model | modèle d'acteur | - |
| borrow | emprunter | - |
| buffer | tampon | - |
| bug | bogue | - |
| callback | fonction de rappel | - |
| cheaper synchronization | synchronisation allégée | - |
| closure | fermeture | - |
| combinator | combinateur | - |
| concurrent | concurrent | - |
| coroutine | coroutine | - |
| CPU | processeur | - |
| crate | crate | - |
| deadlock | interblocage | - |
| driver | pilote | - |
| drop | libérer | - |
| dynamic dispatch | répartition dynamique | - |
| flow controle | contrôle de flux | - |
| framework | cadriciel | - |
| future | future | - |
| GUI application | application avec interface graphique | - |
| heap | tas | - |
| IO | entrée/sortie | - |
| lazy | passif | - |
| library | bibliothèque | - |
| lifetime | durée de vie | - |
| lock | verrou | - |
| low-level | bas-niveau | - |
| mock | mock | - |
| mutable | mutable | - |
| nightly Rust | version expérimentale de Rust | - |
| OS | Système d'Exploitation | Operating System |
| (take) ownership | (prendre) possession | - |
| pin | épingler | - |
| pinning | épinglage | - |
| reactor | réacteur | - |
| refactoring | remaniement | - |
| retry logic | logique de relance | - |
| runtime | environnement d'exécution | - |
| scope | portée | pour la durée de vie |
| shadow | masquer | remplacer une variable par une autre de même nom |
| snip | partie masquée ici | dans un encart |
| stack | pile | - |
| state machine | machine à états | - |
| static | statique | - |
| subscriber | abonné | - |
| task | tâche | - |
| thread | processus | - |
| thread pool | groupe de processus | - |
| trait | trait | - |
| tuple | tuple | - |
| unit test | test unitaire | - |
| unsafe | non sécurisé | - |
| valid | en vigueur | pour la durée de vie |
| yield control | transférer le contrôle | - |